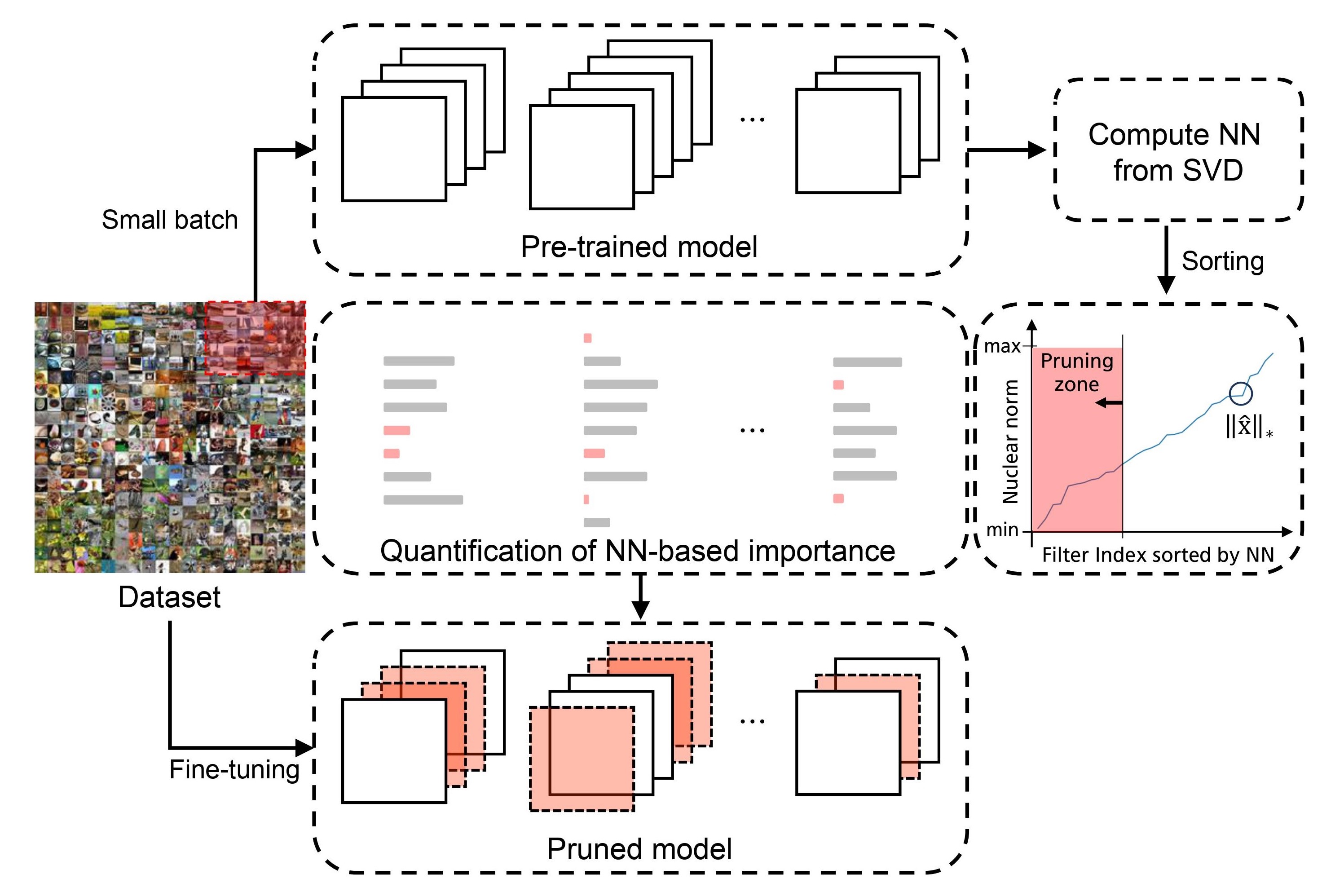
Nuclear Norm Pruning
Toward Compact Deep Neural Networks via Energy-Aware Pruning
For more detailed description on the project, refer to
[arXiv]
Internship as Research Scientist in Nota.Inc
Energy-Aware pruning, or in other words, nuclear norm pruning, was a project that was mainly developed for Nota's primary engine of compressing neural network. Nota, a South Korean incorporation that recently recieved a Series A investment, is a company that focuses in neural network compression. Their main project and commodity, netspresso, offers a whole pipeline including pretrained model, compression, HPO for target device, and completes a full stand alone model. Their primary technology includes pruning, quantization, knowledge distillation,, neural architecture search, and filter decomposition. In Nota, they have a separate division solely for research in model pruning. This division's research is also utilized as part of netspresso's compression model.
I joined in Nota as an intern, by the opportunity given by Yonsei University's startup internship program. Since I had research experience in BigDyl lab of Yonsei university, I had the opportunity to work as a research scientist. The internship program was supposed to last for only 6 weeks, but since I was deeply involved in this project and was writing a paper for submission, I extended my original contract to 2 months and also participated afterwards for paper revisions.
Recall on the project
$$\hat{x} = USV^T = \sum_{i=1}^N\sigma_iu_iv_i^T \quad \cdot \cdot \cdot(1) \qquad \quad ||\hat{x}||_*=\sum_{i=1}^N\sigma_i \quad \cdot \cdot \cdot(2)$$
What was particularly intruiging during the project was the oppotunity to dive into various linear algebra equations. since I was in charge of writing the overall paper, I had to obtain general knowledge of pruning research, which required considerable amount of knowledge in linear algebra. Since it was before I took the computer vision class, it was difficult to catch up, so I started reading numerous papers in the field. It helped a lot in not only my reading skills, but also enhanced my knowledge in linear algebra.
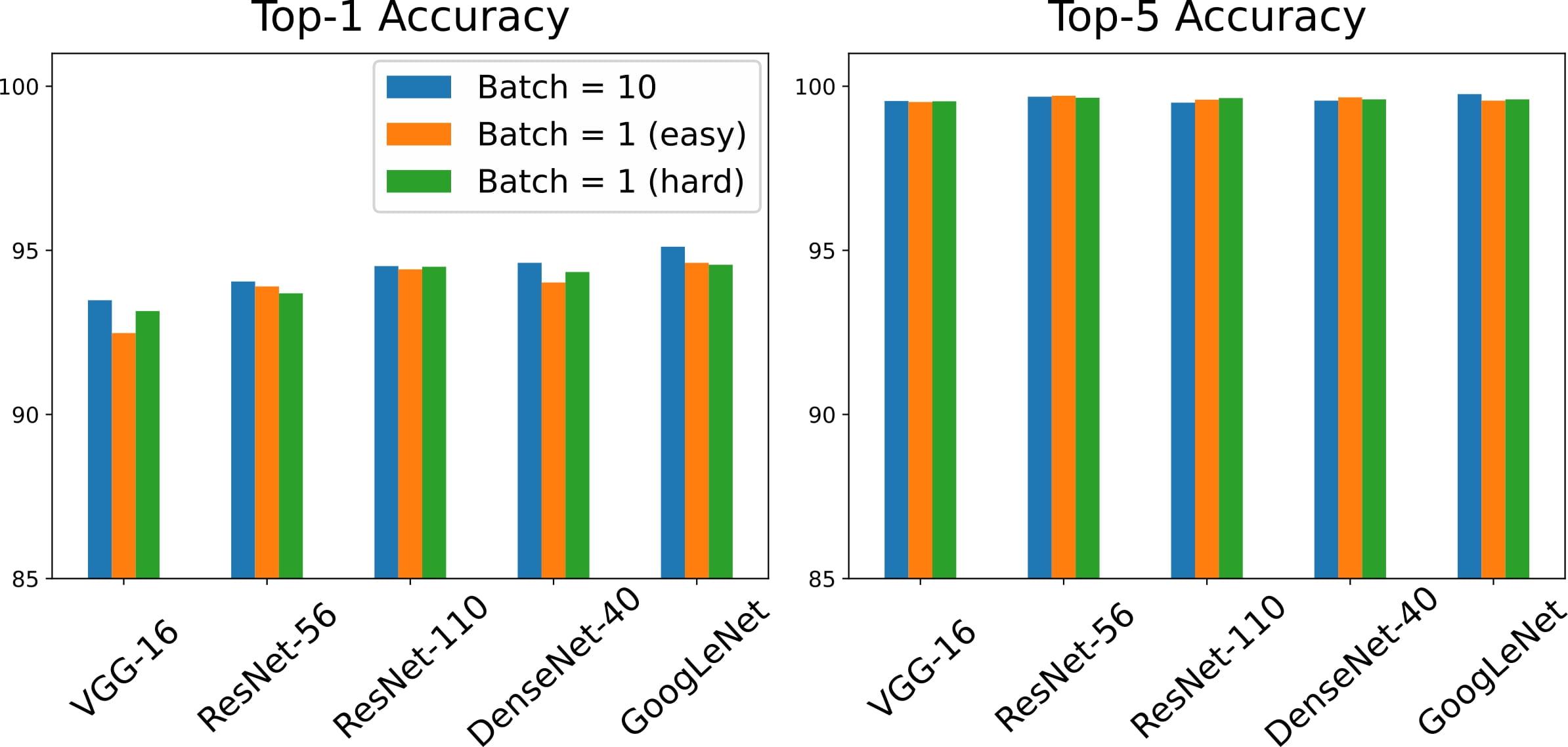
Moreover, since when I joined the project, the concept of using nuclear norm as a pruning criteria was hardened but the supporting experiments and logic was not enough. Therefore, I spent the remaining time mostly on designing ablation studies and logics to support our project. During this process, I designed and implemented experiments where our model was compared in terms of quantity and quality of the data.
Studying in the field of pruning research was interesting for me. However, this actually made me to even more interested in my original field of study, neural differential equations and physics informed neural networks, e.g. Therefore, after a short, concentrated term of internship, I returned back to my lab BigDyl to continue my research.